- Pipecat Evals for executable specifications close to the codebase.
- An evaluation platform for production-like conversations, richer voice analysis, dashboards, monitoring, human review, and longitudinal quality trends.
Lifecycle at a glance
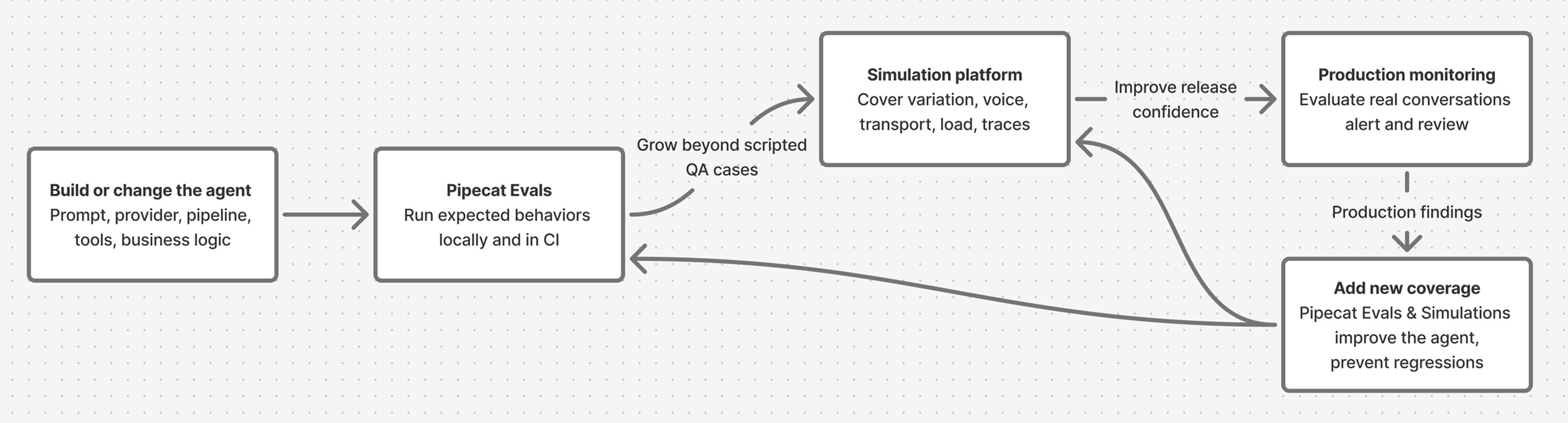
Start local
Use Pipecat Evals as soon as the agent has behavior worth preserving. This usually starts before deployment, while the agent still runs on a laptop or in a pull request. Good local evals look like small executable specs:- “The agent greets on connect.”
- “The agent remembers the user’s name two turns later.”
- “The agent calls
lookup_orderbefore answering an order-status question.” - “The agent recovers when the user interrupts a long answer.”
- “The first response starts within the expected latency budget.”
Put local evals in CI
Once a few scenarios exist, run them on every meaningful change. A small set of behavior-critical scenarios gives engineers and coding assistants a clear pass/fail signal. Use Pipecat Evals in CI when:- The agent is still changing quickly.
- The question is “did this code or prompt change preserve an expected behavior?”
- The expected behavior can be expressed as a scripted conversation.
- The failure should block a pull request.
- The debug artifact should live next to the code as a log or trace file.
When to add a simulation and evaluation platform
Add a platform when the risk you need to test extends beyond a small local scenario. Keep the Pipecat suite in place, then layer on broader coverage, shared workflows, and production feedback.| Signal | Outside Pipecat Evals’ scope | What to add |
|---|---|---|
| Realistic caller behavior matters | Scripted turns prove one path, not how varied users phrase, interrupt, or recover | Simulated callers with varied personas, edge cases, and abuse attempts |
| Voice behavior is part of the product | Transcripts hide TTS loops, clipping, dropouts, phoneme stretch, timbre drift, and odd pauses | Audio-signal metrics, a Speech Artifact Score, and an audio LLM judge that scores the audio itself |
| The deployed transport matters | The local eval transport isn’t a real WebSocket, Pipecat Cloud, SIP, or telephony path | Tests over the deployed path users actually hit |
| Volume and concurrency matter | Local suites skip sustained load, burst traffic, queueing, and service limits | Load tests for concurrency, latency, error rates, and saturation |
| Hidden execution state matters | Transcripts don’t show tool success, arguments, downstream errors, or timing | Trace-based checks on tool calls, span attributes, errors, timing, and custom metrics |
| Product, QA, or Ops need to participate | YAML and CI logs aren’t a shared review workspace | Review queues, per-reviewer assignments, annotations, agreement scores, and dashboards |
| The agent is live with users | Pre-merge checks miss production drift and new real-world failures | Production monitoring that scores live calls and alerts on regressions |
| Deterministic audio regression | Synthesized audio can’t replay the exact call or wording that broke | Exact transcripts and pre-recorded audio as fixed regression cases |
| Comparing releases, vendors, or configs | Local pass/fail can’t do trend analysis or bake-offs | Persisted runs, metrics, recordings, traces, and score distributions |
Choose the right layer
Think of local evals as behavioral unit tests for the agent. Think of an evaluation platform as system testing and quality operations for the agent in the world.Use Pipecat Evals for
Local development, pull-request gates, coding-assistant loops, scripted
behavioral specs, function-call assertions, latency budgets, and fast text
mode iteration.
Use an evaluation platform for
Multi-turn simulations, caller variation, realistic voice and telephony
paths, audio-signal metrics, trace metrics, submitted production calls,
dashboards, human review, scheduled runs, and agent-native CLI, MCP, or
skill-based workflows.
Example: appointment booking
Suppose your Pipecat agent books appointments. Start with a local scenario that protects the core behavior:appointment_booking.yaml
- What happens when the caller changes the time three turns later?
- Can the agent handle an impatient caller who interrupts while it is checking availability?
- Does the agent still work when the caller is in a noisy room?
- Did the booking API actually succeed, or did the agent only say that it did?
- Are users getting frustrated when the available slots are limited?
- Is the booking-success rate drifting after a model or voice-provider change?
Simulate before launch
Local scenarios are intentionally crisp. Platform simulations broaden the same flow across realistic user variation, voice conditions, transport paths, load, abuse attempts, and tool behavior. For regressions that need exact replay, use fixed transcripts, scripted turns, or pre-recorded audio. For tool-heavy flows, include traces so evaluation can check what happened under the transcript: tool calls, arguments, span attributes, errors, timing, and custom numerical metrics from OpenTelemetry. For the appointment agent, a transcript might show:“You’re all set for Tuesday at 3 PM.”A simulation can also check that
book_appointment was called with the
requested day, time, and timezone, that the tool returned success, and that later
spans stayed clear of errors, retry failures, and cancellations.
When judgment matters, route selected conversations to human review. Review
queues, labels, assignments, and agreement scores turn ambiguous calls into
better metrics, tighter ground truth, and better future cases.
Monitor production conversations
Once users are live, send completed production conversations to the platform for monitoring. Score the same quality signals over time, route ambiguous calls into review, and track trends by agent version, transport, scenario, and customer segment.Feed findings back into tests
Production monitoring and human review should create the next evaluation inputs: new local Pipecat scenarios for crisp regressions, new simulation cases for broader user behavior, new trace metrics for hidden tool failures, and new monitoring metrics for recurring production patterns.Practical adoption path
Start small and grow in layers:- Create 5-10 Pipecat scenarios for the agent’s most important scripted behaviors.
- Run the suite in CI and require it before merging prompt, model, tool, or pipeline changes.
- Add audio-mode checks before release for the flows most sensitive to STT, TTS, VAD, and turn-taking.
- Add platform simulations when you need realistic multi-turn behavior, varied callers, telephony or WebSocket coverage, load testing, trace checks, and audio-signal metrics.
- Instrument traces for tool-heavy workflows so evaluations can verify what happened under the hood.
- Expose platform controls to your coding assistant through CLI, MCP, or agent-skill surfaces so the same assistant that fixes local evals can launch simulations, inspect failures, and triage monitoring results.
- Send production calls to monitoring once users are live, then turn recurring failures into new simulations, metrics, human-review projects, or local scenarios.
Next steps
Pipecat Evals Quickstart
Write and run the first local scenario against an existing agent.
Third-party Platforms
Review the available platform integrations for simulation and monitoring.
Writing Scenarios
Learn the YAML format for turns, expectations, function calls, interruptions,
latency budgets, and audio mode.
Example Platform Setup
See one concrete setup path for simulations, monitoring, traces, and team
review workflows.